When asked what Kubernetes is, most people will answer with “a container orchestration system”.
This is a good factual statement of the what, but it misses the why and how, which are much more important for developing a good understanding of Kubernetes.
In this article, we’ll explore why and how Kubernetes is (instead of the what), and why containers are just an implementation detail and not the main point of Kubernetes.
If “Kubernetes = Docker but highly complex” is you, read on. I’ll try to correct some misunderstandings in this post. Otherwise, you may be interested in my next post on declaratively running Kubernetes without building up bad state (link at the end of this article).
So what why is Kubernetes?
Think of Kubernetes like an operating system (OS).
In a traditional OS you have resources like CPU, memory, and storage. The job of the OS is to schedule which software gets what resources at any given time.
Kubernetes does the same thing. You have resources on each one of your nodes, and Kubernetes assigns those resources to the software running on your cluster.
For our purposes, there are two key differences between Kubernetes and a traditional OS.
The first difference is the way you define what software to run. In a traditional OS, you have an init system (like systemd) that starts your software. In Kubernetes, you define objects, and Kubernetes uses these objects to configure and run the software you specify. Objects are similar to those in programming languages: they are typed and contain data specific to their type.
The second difference is that Kubernetes works across multiple computers. In a traditional OS, you need to decide what software gets deployed to what machine. With Kubernetes, you deploy one piece of software to the entire cluster, and Kubernetes figures out what machine to run it on based on the rules you give it. For example, you might say you want to run IPython notebooks on any node with a GPU, and run your web apps on nodes without GPUs.
Notice how my definition of Kubernetes doesn’t include the word “container”. This is on purpose. The main idea behind Kubernetes is declarative infrastructure management, not running containers. Someone could also have implemented the ideas behind Kubernetes but with VMs or processes as the smallest compute units.
Credit: I heard this analogy first from ~fydai.
What kinds of Objects are there?
As mentioned in the previous section, the main idea behind Kubernetes is its object system. All objects have some basic fields (like their name, uid, and user-customizable labels), and many common objects additionally have a namespace that helps keep logical groups of objects separate.
Here are some common object types, and what you might use them for. Obviously, some of these are oversimplified (a Deployment actually makes a ReplicaSet not a Pod), but we’re ignoring details for now.
Pod - A small group of containers (but is usually just one container). Note: Containers follow the OCI standard, meaning any image built by any OCI-compatible software (like Docker, Podman, etc.) will work on any other OCI-compatible runner.
Deployment - A group of pods, with some basic fields for things like the number of replicas to deploy.
Service - A group of ports that point to pods, depending on some user-specified rules.
Ingress - Expose your service with some rules, such as the hostname to respond on. This requires an Ingress provider like nginx to be installed on your cluster (more on this in a later post).
PersistentVolumeClaim - A reference to a persistent filesystem that you can store your data in. This requires a pvc provider to be installed on your cluster- which range from local filesystem storage on one node to distributed storage with Ceph (more on this in a later post).
CustomResourceDefinition - It is also possible to make your own types, and write your own logic to determine what they do. This can allow you to create higher level objects like PostgresInstance or MonitoringEndpoint. This is known as the “Operator Pattern” and is beyond the scope of this article.
These objects are your Kubernetes building blocks. To deploy software, you just need to combine them in various ways to serve your needs.
Let’s look at an example.
Example: A Typical Web App
To make this less scary, let’s do this without looking at the actual objects. Objects are typically written in YAML, but this was a bad design choice by the designers of Kubernetes. Most typical uses will require generating YAML in some way, which I’ll talk more about in the next article. If you want to read the YAML I used for this, check out this gist.
Say we have an OCI image that contains a web app that listens on port 8080. To represent this in Kubernetes, we will use a Pod.

The Pod definition will contain some variables that we set, such as the image reference (k8s.gcr.io/echoserver:1.4), the pod name (echo), some resource requests (100MB RAM and half a CPU core), a label (app=echo), and the port that it listens on (8080).
When we add this object to the cluster, Kubernetes will run the container on an available node that has enough compute resources. However, a Pod is an ephemeral unit. If it crashes or stops, it won’t restart. To fix this, we’ll wrap our Pod object in a Deployment object.

The Deployment definition will have a name (echo), a label (app=echo), and a copy of the Pod object definition we wrote earlier.
Remember, a Deployment object creates Pod objects according to some specification. For now, we’ll create just one.
We’ll then add the Deployment object to the cluster by running kubectl apply -f my_definition_file.yaml, and pretty soon we can see both the Deployment and the Pod it made in kubectl get deployment or kubectl get pod.
Next we need a way to access the deployment. To do this, we’ll use a Service and an Ingress.

The Service will point to port 8080 on all Pods that are labeled app=echo, and the Ingress will route all traffic on echo.example.com to the Service with the name echo.
If we visit echo.example.com, we’ll see our echo service! Hooray!
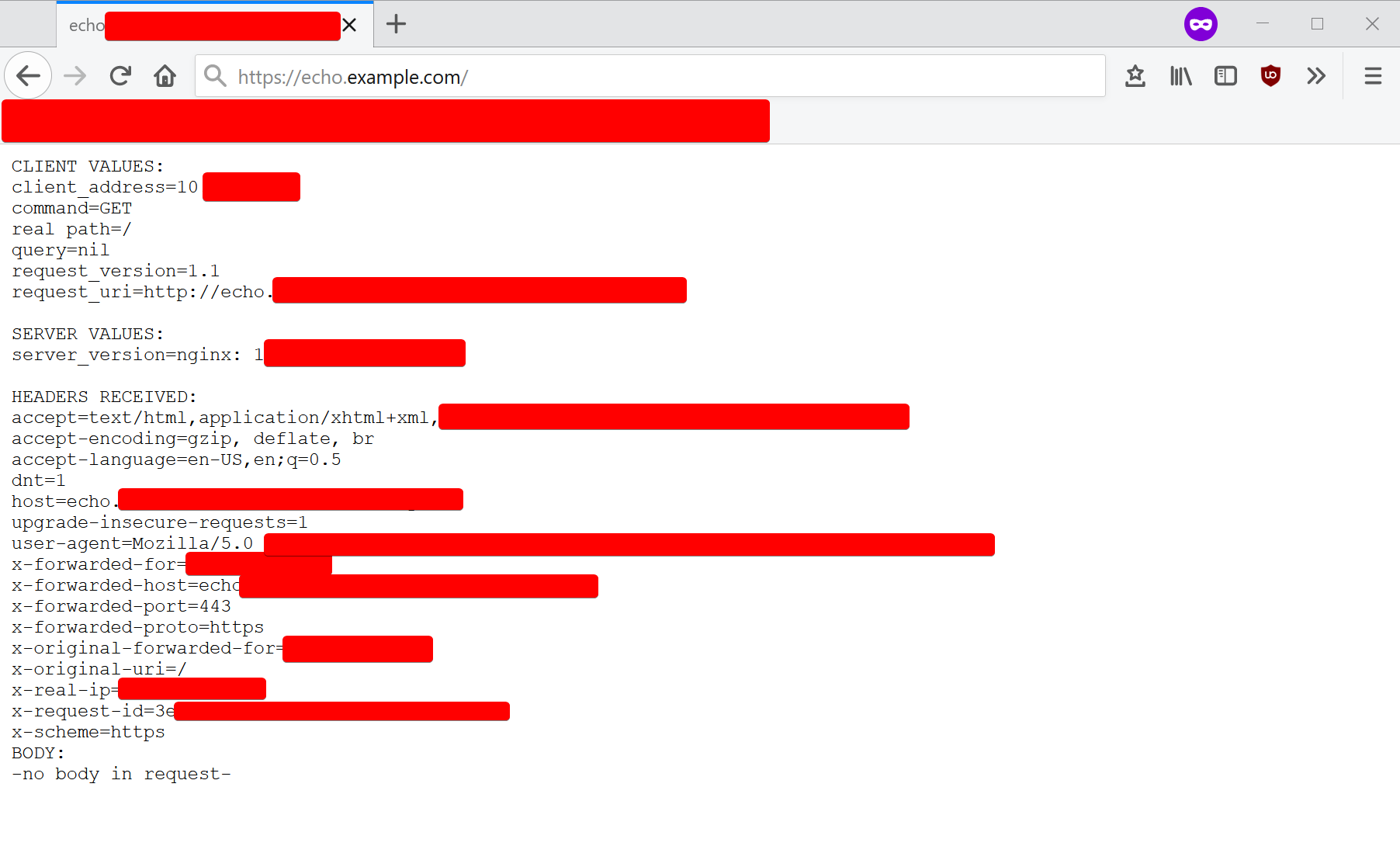
But wait, there’s more. Remember when I said that using a Deployment to manage our Pod would give us an extra-cool feature?
Let’s see what happens when we set replicas to 2 in our Deployment.
.svg)
The deployment makes two pods!
Now, even if one Pod crashes, the other one is still around to serve requests, while the other one restarts! We’ve successfully deployed Highly Available HTTP Echo™!
Hopefully this gave you a good idea of how to use the various Kubernetes building blocks to define infrastructure.
Next Time
In my next post, I’ll talk about how you can declaratively setup and manage your Kubernetes cluster without building up bad state or having to manage too much YAML.
To make sure you don’t miss it, consider adding my website to your RSS reader.
Here are the Kubernetes-related articles I’m working on…
- How can you setup and manage your Kubernetes cluster without building up bad state? (Coming Soon)
- What components make up a typical Kubernetes distribution & how do they work together? (Coming Less Soon)
- Maybe more, if I can power through writing more.